BERT(Bi-directional Encoder Representations from Transformers)
- 구글에서 개발한 NLP 사전 훈련 기술, Language Model
- 잘 만들어진 BERT 언어모델 위에 1개의 Classification layer만 부착하여 다양한 NLP task를 수행
- Contextual Embedding 방법
: 단어마다 벡터가 고정되어있지 않고 문장마다 단어의 vector가 달라지는 임베딩 방법을 뜻한다.

BERT 모델의 구조도
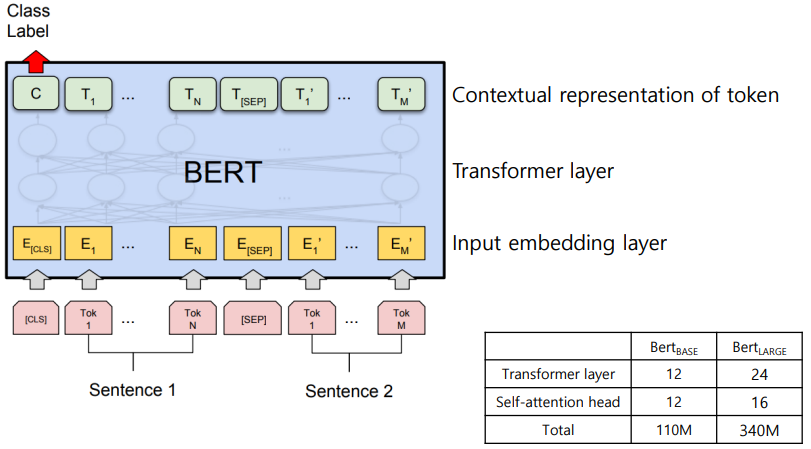
- Sentence 2개를 input으로 받아 토큰 단위로 임베딩
- Transformer layer를 거친다.
- 최종적으로 자신을 표현하는 구조
WordPiece tokenizing
- Byte Pair Encoding(BPE) 알고리즘 이용
- 빈도수에 기반해 단어를 의미 있는 패턴(Subword)으로 잘라서 tokenizing
- "He likes playing" 이라는 문장이 있다면,
~ing 처럼 빈도수가 비교적 높은 charater 단위를 빈도수에 따라 분리하는 tokenizing 방법
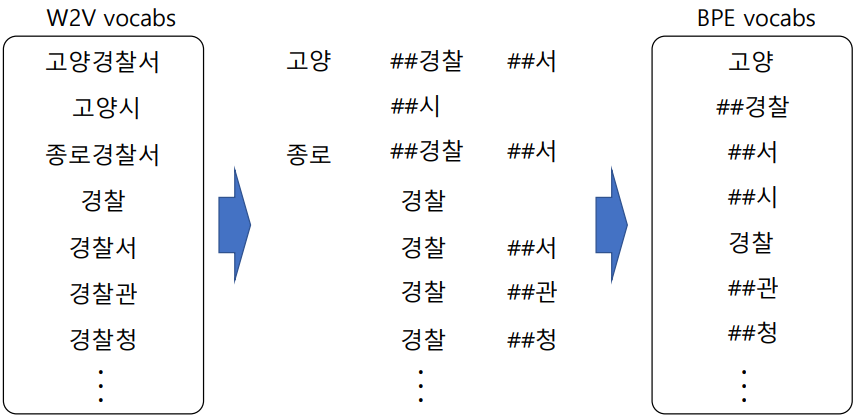
BPE 순서도

Masking 기법
- 데이터의 tokenizing
- Masked language model(MLM) : input token을 일정 확률로 masking

- 학습 데이터의 첫 문장을 하나 가져온다.
- 이 때 앞에 [CLS]를 붙이고 뒤에는 [SEP]라는 토큰을 붙인다.
- 토큰 중 Randomly하게 15%를 선택한다.
- 15% 중 80%는 [Mask]로 바꾸고
- 나머지 10%는 Randomly하게 다른 단어를 선택하여 그 단어로 Replacing
- 나머지 10%는 Unchanging
- 이 과정의 결과로 만들어진 문장을 BERT의 input으로 넣게 된다.
- 앞의 BERT 구조도를 보면 Input으로 문장 2개가 들어간다 - 그리고 출력에서 Input Sentence를 예측하도록 학습이 이루어진다.

- Input으로 2개의 문장이 들어간다.
- 첫 번째 또는 두 번째 문장에서 [MASK]된 것이 있을 수 있다. - Transformer Layer를 거쳐 원래의 문장을 예측하는 방식으로 이루어진다.
- 이때 MASK된 단어마저도 원래의 단어를 예측하도록 학습된다.
- 두 번째 학습은 문장 2개를 선택함에 있어 학습데이터를 만들 때, 두 번째 문장은 Corpus의 다음 문장으로 만들수도있고, 50%의 확률로 완전 다른 곳에서 Random하게 가져올 수도 있다.
- 가져오면 IsNext인지 NotNext인지 Class layer에서 같이 학습하게 된다.
- Class Layer도 연관 레이블을 가지고 있어 학습하게 된다. - 학습 총 2가지
1. Next Sentence를 예측하는 걸로 BERT가 Transformer로 학습
2. MASK 혹은 Replace된 단어마저도 정답을 맞힐 수 있도록 학습 - 이렇게 두 가지 학습으로 BERT가 학습 데이터로 사용된 언어를 모델로서 표현하게 된다.
- Input은 단순히 Vocab으로 토큰들이 들어가는 것이 아니다.
- 첫 번째는 토큰에 대하여 Embedding Layer를 하나 거친다.
- Word Embedding Layer 한 칸이 달려있어, 입력 토큰에 대한 word embedding 거친다.
- Word Embedding : 단어를 벡터로 표현하는 방법. 단어를 밀집 표현으로 변환 - 다음으로 Segment Embedding을 거친다.
- 문장 A인지 B인지에 대해 Embedding Layer를 거쳐 학습이 이루어진다. - 또 하나론 Position Embedding을 거친다.
- 토큰이 그림처럼만 들어간다면 BERT에서 순서에 대한 정보를 얻을 수 없기 때문에,
position embedding을 거쳐 토큰 개수에 따라 position embeding을 다르게하여 학습이 이루어지게 된다.
Methods
- BERT-BASE모델과 BERT-LARGE 모델 2가지를 발표
- LARGE 모델의 성능이 더 좋다.

BERT에서 Classification Layer를 다르게 하여 task 수행하는 4가지 종류

- Sentence pair classification
- 두 가지 문장을 넣고 두 문장이 어떤 관계를 가지는지 표현
- 예) 두 문장이 자연스로운 흐름이다, 의미상 유사하다 - Single sentence pair classification
- Single sentence를 입력으로 넣고 분류한다.
- 예) 영화리뷰를 넣고 긍정인지 부정인지, 아무 의미 없는 중립인지 분류 - Question and answering
- 질문이 들어가고, 그 질문에 대한 답을 포함하는 Paragraph가 들어감으로써 답변을 찾아낸다.
- 답변을 Paragraph의 index값을 출력한다. - Single sentence tagging
- 각 토큰에 대한 출력을 만들어낸다.
- 입력받은 문장을 tokenizing한 각 토큰에 대한 어떤 정보값을 내는 것
- 예) "나는 SK 텔레콤에 있다" -> SK는 기관명의 시작, 텔레콤은 기관명의 끝
- BIO 태그, 시작, 중간, 끝에 있는 태그인지 등의 구조를 이용해 학습
BERT 적용 실험 - QnA 문장 유사도 (이진 분류 기반)
- 디지털 동반차 패러프레이징 질의 문장 데이터를 이용해 질문-질문 데이터 생성 및 학습
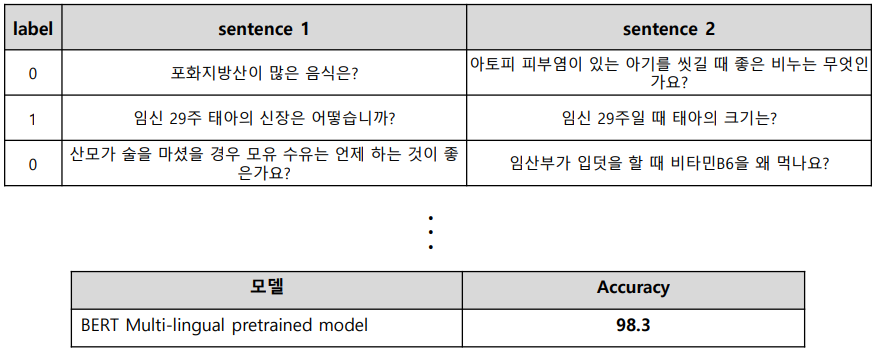
- 단점 : 사람이 보기에도 의미가 모호한 문장들은 구분하기 힘들다.
- 공부한 URL
1. Tacademy 강의 https://www.youtube.com/watch?v=qlxrXX5uBoU
'학교 > 졸프' 카테고리의 다른 글
| TF-IDF (0) | 2021.05.05 |
|---|---|
| Faiss (0) | 2021.05.01 |
| KcBERT 실습해보기(2) (0) | 2021.04.21 |
| KcBERT 실습해보기(1) (0) | 2021.04.16 |
| 자연어처리 및 언어모델 (0) | 2021.04.12 |